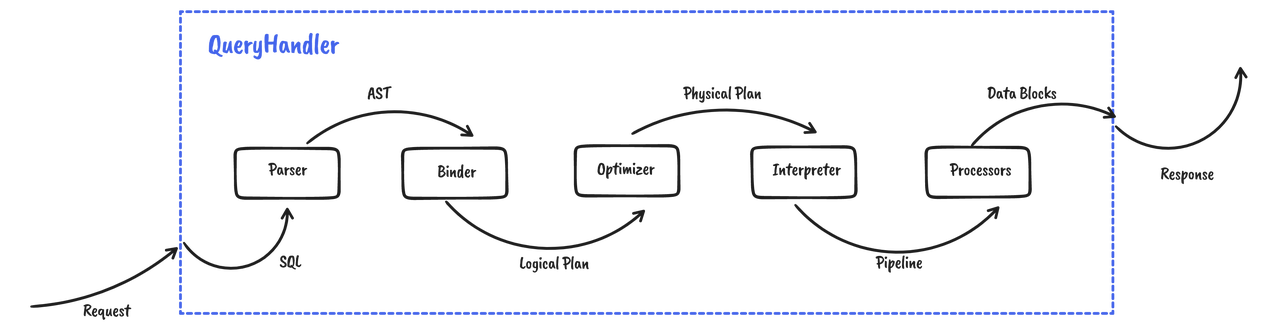
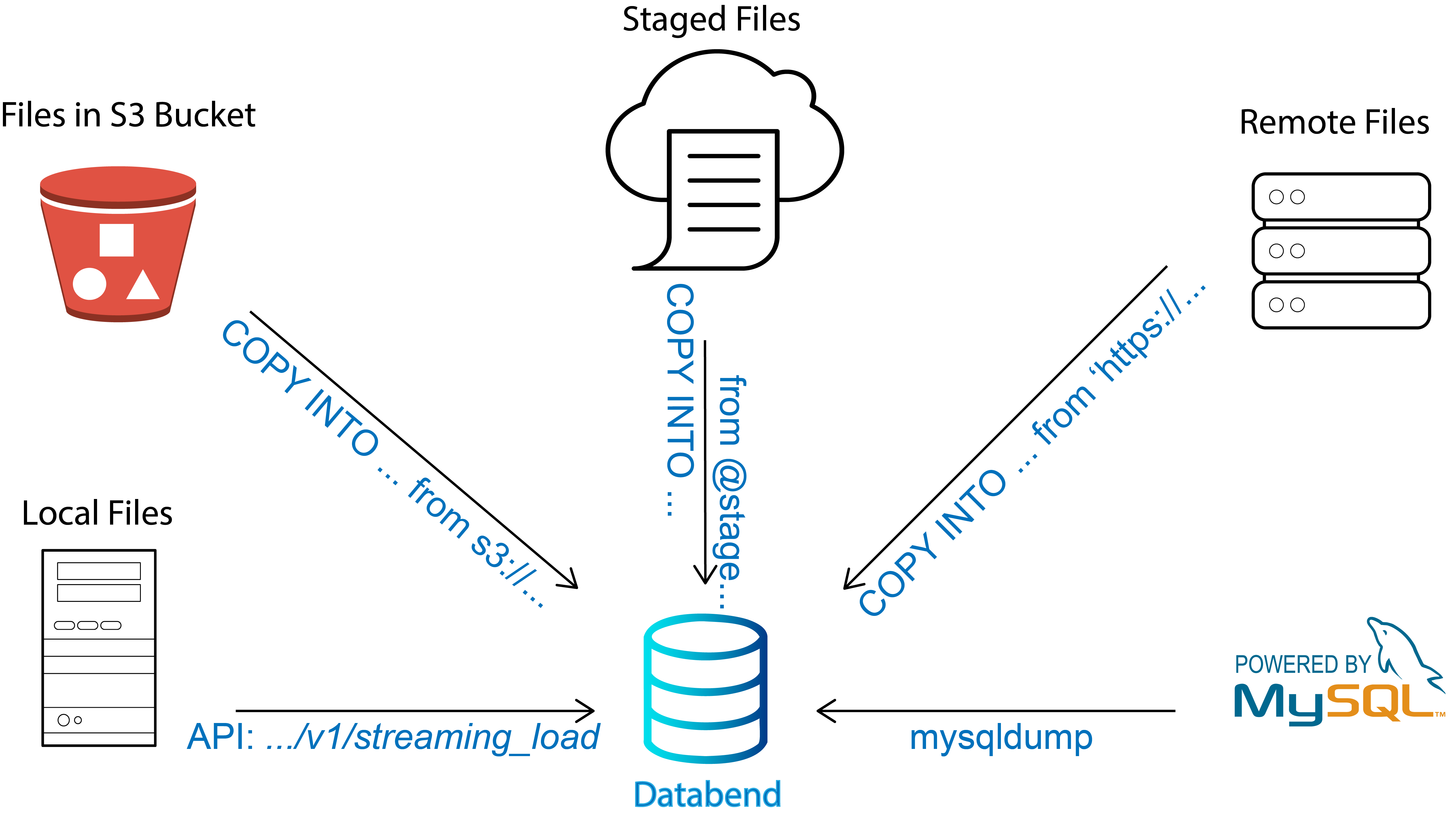
Databend is a powerful cloud data warehouse. Built for elasticity and efficiency. Free and open. Also available in the cloud: https://app.databend.com .
What's New
Check out what we've done this week to make Databend even better for you.
Features & Improvements ✨
Format
Query
Storage
- add cache layer for fuse engine (#8830)
- add system table system.memory_statistics (#8945)
- add optimize statistic ddl support (#8891)
Code Refactoring 🎉
Base
- remove common macros (#8936)
Format
- TypeDeserializer get rid of FormatSetting (#8950)
Planner
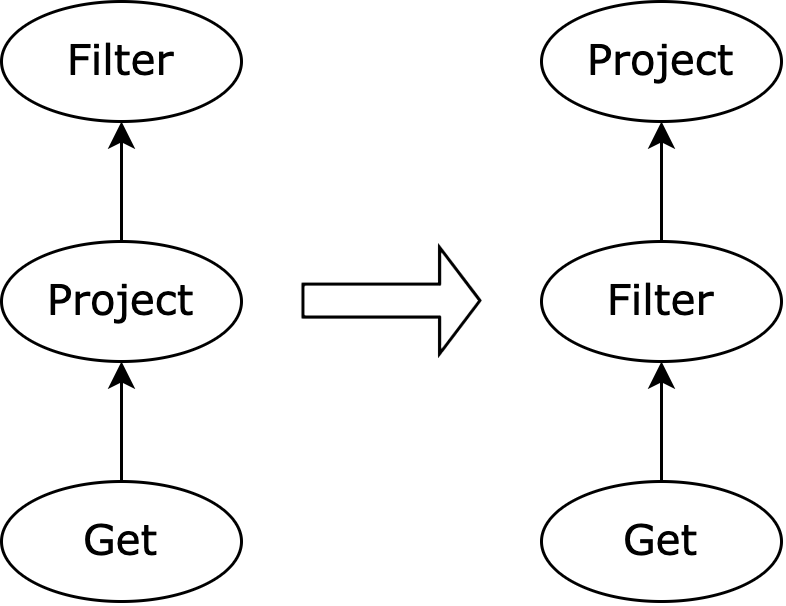
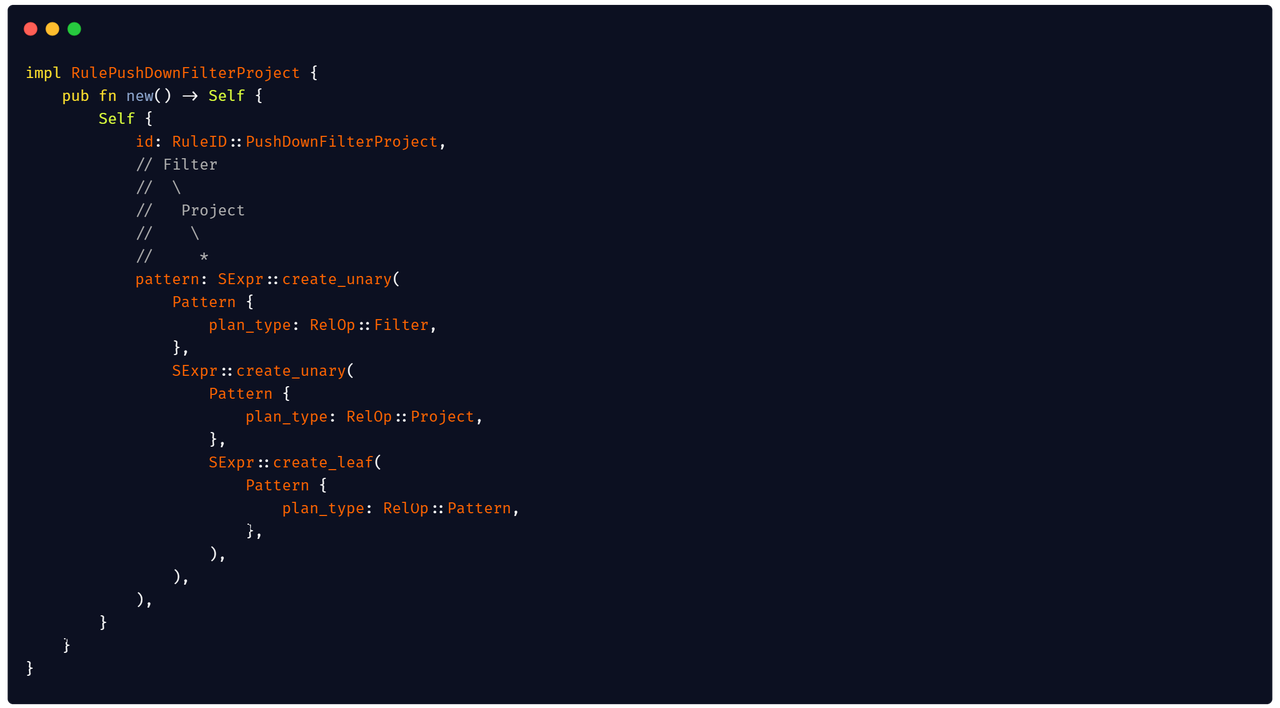
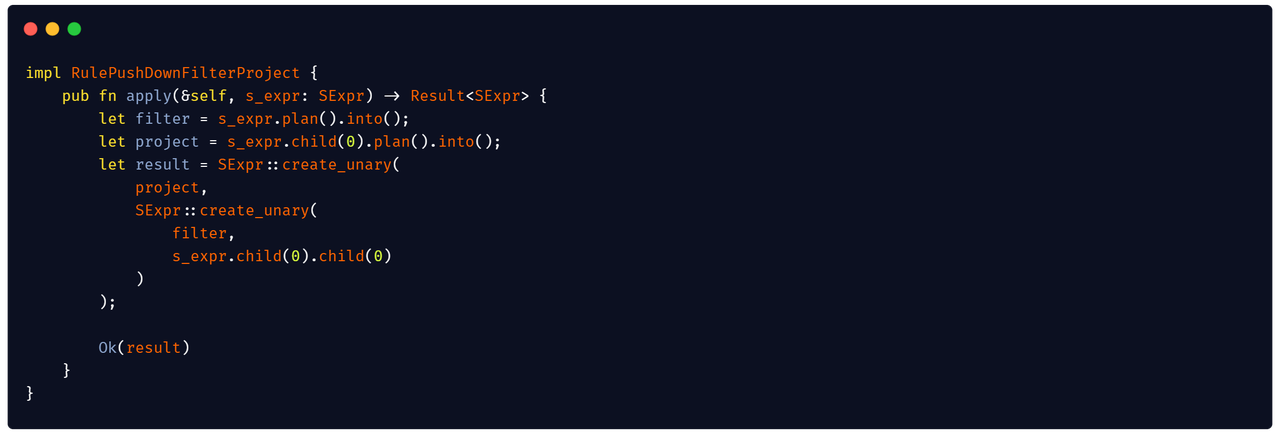
- refactor extract or predicate (#8951)
Processors
- optimize join by merging build data block (#8961)
New Expression
Documentation 📔
Bug Fixes 🔧
Base
- try fix lost tracker (#8932)
Meta
- fix share db bug, create DatabaseIdToName if need (#9006)
Mysql handler
- fix mysql conns leak (#8894)
Processors
- try fix update list memory leak (#9023)
Storage
- read and write block in parallel when compact (#8921)
What's On In Databend
Stay connected with the latest news about Databend.
Infer Schema at a Glance
You usually need to create a table before loading data from a file stored on a stage or somewhere. Unfortunately, sometimes you might not know the file schema to create the table or are unable to input the schema due to its complexity.
Introducing the capability to infer schema from an existing file will make the work much easier. You will even be able to query data directly from a stage using a SELECT statement like select * from @my_stage.
INFER 's3://mybucket/data.csv' FILE_FORMAT = ( TYPE = CSV );
+-------------+---------+----------+
| COLUMN_NAME | TYPE | NULLABLE |
|-------------+---------+----------|
| CONTINENT | TEXT | True |
| COUNTRY | VARIANT | True |
+-------------+---------+----------+
We've added support for inferring the basic schema from parquet files in #9043, and we're now working on #7211 to implement select from @stage.
Learn More
- PR | add basic schema infer for parquet
- Issue | query data from S3 location or stage
- PR | rfc: Infer Schema
What's Up Next
We're always open to cutting-edge technologies and innovative ideas. You're more than welcome to join the community and bring them to Databend.
Add Tls Support for Mysql Handler
opensrv-mysql v0.3.0 that was released recently includes support for TLS. It sounds like a good idea to introduce it to Databend.
let (is_ssl, init_params) = opensrv_mysql::AsyncMysqlIntermediary::init_before_ssl(
&mut shim,
&mut r,
&mut w,
&Some(tls_config.clone()),
)
.await
.unwrap();
opensrv_mysql::secure_run_with_options(shim, w, ops, tls_config, init_params).await
Issue 8983: Feature: tls support for mysql handler
Please let us know if you're interested in contributing to this issue, or pick up a good first issue at https://link.databend.rs/i-m-feeling-lucky to get started.
Changelog
You can check the changelog of Databend Nightly for details about our latest developments.
- v0.8.136-nightly
- v0.8.135-nightly
- v0.8.134-nightly
- v0.8.133-nightly
- v0.8.132-nightly
- v0.8.131-nightly
- v0.8.130-nightly
- v0.8.129-nightly
- v0.8.128-nightly
- v0.8.127-nightly
- v0.8.126-nightly
Contributors
Thanks a lot to the contributors for their excellent work this week.
 |  |  |  |  |  |
|---|---|---|---|---|---|
| andylokandy | ariesdevil | b41sh | BohuTANG | dantengsky | drmingdrmer |
 |  |  |  | ![mergify[bot]](https://avatars.githubusercontent.com/in/10562?v=4&s=117) |  |
|---|---|---|---|---|---|
| everpcpc | flaneur2020 | leiysky | lichuang | mergify[bot] | PsiACE |
 |  |  |  |  |  |
|---|---|---|---|---|---|
| sandflee | soyeric128 | sundy-li | TCeason | TracyZYJ | Xuanwo |
 |  |  |  |  |
|---|---|---|---|---|
| xudong963 | youngsofun | yufan022 | zhang2014 | zhyass |
Connect With Us
We'd love to hear from you. Feel free to run the code and see if Databend works for you. Submit an issue with your problem if you need help.
DatafuseLabs Community is open to everyone who loves data warehouses. Please join the community and share your thoughts.
- Databend Website
- GitHub Discussions (Feature/Bug reports, Contributions)
- Twitter (Get the news fast)
- Slack Channel (For live discussion with the Community)